问题介绍多臂老虎机问题[1]是概率论中一个经典问题,也属于强化学习的范畴.设想,一个赌徒面前有N个老虎机,事先他不知道每台老虎机的真实盈利情况,他如何根据每次玩老虎机的结果来选择下次拉哪台或者是否停止赌博,来最大化自己的从头到尾的收益.关于多臂老虎机问题名字的来源,是因为老虎机[2]在以前是有一个操控杆,就像一只手臂(arm),而玩老虎机的结果往往是口袋被掏空,就像遇到了土匪(bandit)一样棋牌游戏,而在多臂老虎机问题中,我们面对的是多个老虎机.商业应用在商业中,多臂老虎机问题有着广泛的应用,包括广告展示,医学试验和金融等领域[3].比如在推荐系统中,,我们有N个物品,事先不知道用户U对N个物品的反应,我们需要每次推荐给用户某个物品,来最大化用户的价值(或者说尽量使得用户U转化),比如用户的购买. 问题建模每个物品

被用户U转化的事件,对应一个伯努利分布

,

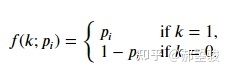

我们叫做

的被转化率.换句话说,就是对于每个物品,用户U转化的概率为
,其中

.我们事先是不知道每个物品对应的被转化率
的.想对伯努利分布和二项式分布,泊松分布,指数分布的关系有所了解的同学请戳EE问题EE(Exploration and Exploitation,探索和利用)问题在这个情景下,探索(Exploration)指的是推荐新的物品给用户,开发用户的兴趣点;而利用(Exploitation)指的是利用当前收获的信息来最大化收益,保证用户当前的体验,比如我们在前几次推荐中,发现用户很喜欢物品i,我们之后利用这个信息来多推荐物品i.

EE问题(Exploration and Exploitation Dilemme)Epsilon-greedy对应得,我们有

(叫做epsilon-greedy),指的是在N个物品之间选择一个给用户推荐(拉哪台老虎机)时,以

的概率在N个物品之间等概率随机选择.以

的概率在N个物品之间选择被转化率最高的那个,也就是

.其中

,
越大,探索的程度越大.以下是简化的代码实现import numpy as np
N = 3
T = 100
epsilon = 0.1
P = [0.5, 0.6, 0.55]
def pull(N, epsilon, P):
"""通过epsilon-greedy来选择物品(拉老虎机)
Returns:
本次选择的物品
"""
# 通过一致分布的随机数来确定是搜索还是利用
exploration_flag = True if np.random.uniform() <= epsilon else False
# 如果选择探索
if exploration_flag:
i = int(min(N-1, np.floor(N*np.random.uniform())))
# 如果选择利用
else:
i = np.argmax(P)
return i
def trial_vanilla(rounds=T):
"""做rounds轮试验
rewards来记录从头到位的奖励数
"""
rewards = 0
for t in range(rounds):
i = pull(N, epsilon, P)
reward = np.random.binomial(1, P[i])
rewards += reward
return rewards估计每个物品的被转化率在
章中,我们提供了简化的代码.这个代码简化之处在于:我们假设已经知道了每个物品的转化率

,但实际上这是不知道的.为了估计
,通常有两种做法:UCB(Upper Confidence Bound) 2. Thompson Sampling关于这两种做法,后面的文章我会详细介绍.参考^多臂老虎机 https://en.wikipedia.org/wiki/Multi-armed_bandit^单臂老虎机 https://en.wikipedia.org/wiki/Slot_machine^intro to MAB https://www.mosaicdatascience.com/2019/07/17/reinforcement-learning-intro-multiarmed-bandits-1/








